
Recipe Generation From Image Input
Improving upon past research by introducing transformers
For the full research paper please click here.
Introduction
In one of my most recent Masters courses focused on Deep Learning, I was asked to form a group and conduct research using the new concepts I had learned. My team and I came across work done by an MIT team (Learn More/Full Paper) where they created a multi-modal embedding of ingredient and instruction text and food image pictures webscrapped from popular cooking sites. This dataset was known as Recipe1M and was one of the first to contain rich text and image data with 1 million text datapoints and 800,000 image datapoints. The MIT models architecture can be seen below:
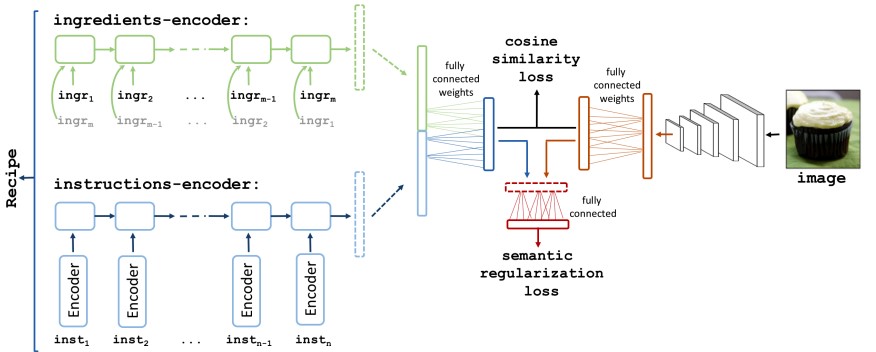
The MIT team used joint encoder embeddings with a Cross Entropy and semantic regularization loss. This model was able to correctly predict the ingredients in a food image within the top-ten ingredients of the prediction rankings with a recall of around 70%, but took the researchers 3 days to train on 4 machines with large memory. These results were successfully reproduced. My team did not have this much time to train the model if we wanted to iterate over our propsed improvements. As a result, the two major goals we defined were improving the recall scores compared to the MIT model and finding a way to train the model in a shorter amount or time with less resources.
Our Approach and Results
It was clear to the team that the only way to reduce the training time for the model was to cut back on the size of the dataset by only training on a portion of it. I decided to treat this as a situation of low labelled data, attempting to few-shot learn a model. I did this by beginning with a pre-trained VGG-16 model, freezing the parameters, adding a new classification layer at the end of the model, and training this classification layer on a few examples from the Recipe1M dataset, 5 examples for each class. This was only able to achieve around 13% recall due to the fact that this was a pure vision model. The Recipe1M dataset gets it's strength from its multi-modal data and was not optimized for use with a vision model.
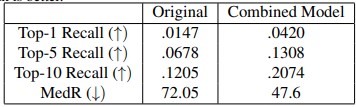
For the next idea, we decided to proceed with only 1% of the dataset and train new model architectures from scratch. To provide a new baseline, the MIT model was re-trained on the subset of the dataset. Their model achieved 12% recall for top-10 rankings and a median recall of around 72, setting the bar for our model experimentation. The first alteration we experimented with was changing the Cross-Entropy loss function for the baseline model. Though when re-trained with MSE loss, the model performance was negatively impacted.
Still seeking model improvements, the team focused in on the embedding for recipe and image data. The baseline model was using word2vec and a bidirectional LSTM for recipe embeddings, but with the recent craze around transformers we wanted to give that a try. The textual embedding was replaced with a pre-trained all-MiniLM-L6-v2 sentence transformer which successfully produced embeddings as shown below for 10 classes.
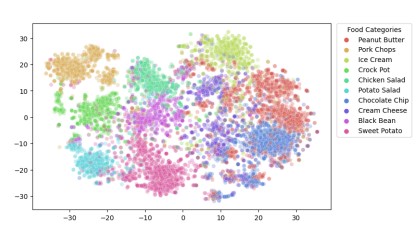
This change resulted in a slight improvement to top-ten recall of 1-2%. With this slight success, we decided to try the same approach for the visual embedding, replacing the ResNet portion with a pre-trained ViT as advised by previous transformer research that exhibited ViT's higher performance than ResNet for some problem domains. The new vision embedding proved successful, reducing the median recall to only 47. We were on the right track.
Finally, we combined our two successful experiments and re-trained the model with transformer embeddings for both the text and image data. Reaping the benefits of self-attention, the combined model resulted in a 3 times improvement in top-1 recall and a 33% reduction in median recall!
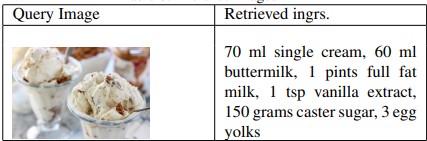
The model also passed the eye test as we ran a few example images through the model and observed what ingredients were predicted for the dish.
